Roger Components Architecture diagram
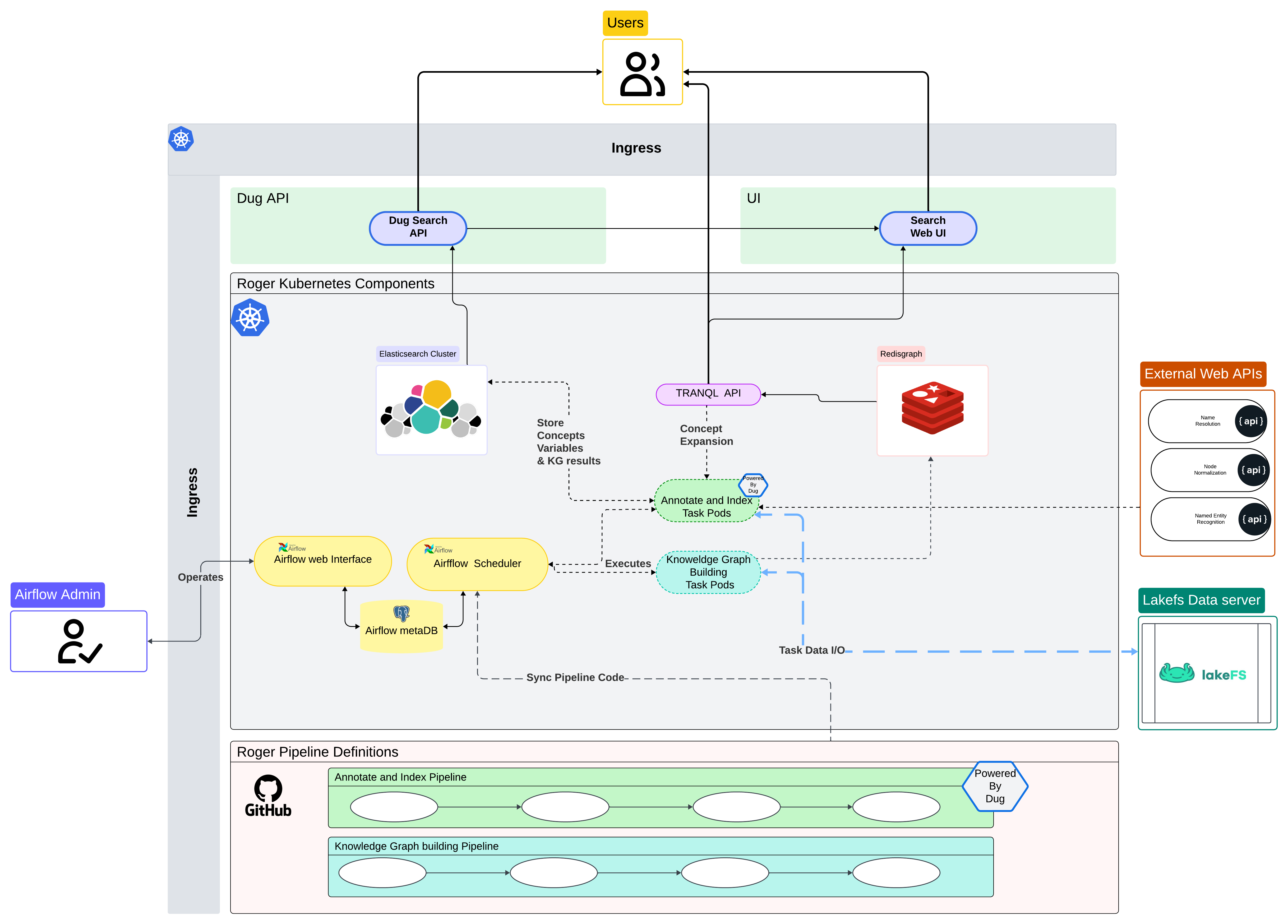
The purpose of the Roger package is to break down pieces of the Dug system into independent components that can be scheduled, managed, and orchestrated independently. This allows the Dug system to be scaled to much larger sizes than would be possible than when trying to run Dug on a single operating system instance.
Roger does this with organizing functions in a python library which makes calls into the internal Dug library code. In so doing, Roger breaks down both the pipeline tasks into manageable steps as well as allowing tasks such as orchestration to be split off into separate containers or instances in order to parallelize key tasks.
Roger orchestration pipelines
There are two primary data pipelines, which are explained more in the development guide. One assembles the accumulated knowledge graphs into single knowledge graph database for querying by the annotator. The other takes data set metadata from various sources and passes it through a series of parsers and annotators before creating documents to be indexed in the ElasticSearch engine.
Roger provides multiple ways of executing these steps. Each of the steps can be called with a command line utility. Further, there are Makefiles which produce these steps. The core development effort, however, focuses on orchestrating these steps with a set of Apache Airflow directional acyclical graph (DAG) definition files.
Multi-container execution environment for Roger
Roger is developed with the assumption that different components can be run independently. In the reference implementation of Roger, this is achieved with Kubernetes, but the same division of tasks may be applied to any similar container, virtual instance, or similar partitioning solution.
Dug Search UI and Web API endpoint services (ui and api services)
The Dug project proper provides services for running both a web UI server and its backing REST API service as user-accessible endpoints. While these could be run on the same instance, in the reference implementation, these are run in separate containers.
ElasticSearch Cluster instances (elasaticsearch-master-[1-3])
The Dug REST API reformats search queries and passes them on to the ElasticSearch (ES) cluster instances. the reference implementation of Roger launches a three-member cluster in order to serve queries to the search engine. The ES API endpoint which forwards to the cluster also receives index calls from the pipeline orchestration components when the search index is being built.
Redis graph database and Insight GUI (redis-master and redis-insight)
The knowledge graph is hosted in the Redis key-value store using the FalkorDB extension. The reference implementation launches a single redis database instance, along with an optional separate instance to serve the Redis Insight GUI, should it be wanted.
TranQL API
The TranQL API provides a REST endpoint for running knowledge graph queries against the Translator graph as well as serving a visualization engine for the knowledge graph. At present this is the primary method by which the data pipelines use the knowledge graph to perform concept expansion.
Apache Airflow pipeline orchestration (scheduler, web, and postgresql)
While Roger can work with multiple different orchestrators, the reference implementation uses Apache Airflow to execute and monitor the pipelines discussed above. Airflow in particular runs a web server for the Airflow administrative user interface, at least one scheduler instance for launching tasks, and a PostgreSQL database for storing pipeline state information and other system metadata.
External services
Depending on the Roger configuration, there are multiple external services which
are required for Roger tasks to complete that do not run as part of the core
Roger service framework. The first three are part of the annotate_and_index
pipeline which ingests dataset metdata documents into the indexer. The last,
LakeFS, is an optional component which allows for iterative indexing and
resumption of execution after partial errors without restarting the full
pipelines.
All of these services are accessed over REST APIs.
Named Entity Recognition (NER) engine
The NER engine accepts blocks of text or metadata and uses specially trained machine learning language processing tools to find entities in the text that correspond to biomedical concepts. These concepts are then annotated with a compact universal resource identifier (CURIE), allowing them to be resolved to specific points on the knowledge graph in the following steps.
Name resolver
The name resolver API attempts to resolve synonyms into similar concepts. In the
Dug workflow, the annotate_and_index pipeline passes individual CURIEs to the
name resolver, which responds with a list of CURIEs that can be used as synonyms
for the input.
Node normalizer
Using the BioLink Model registry as an ontological base, the node normalizer accepts individual CURIEs and resolves them to a preferred synonym, as well as identifying the semantic type under the BioLink Model. This allows for the simplification of the knowledge graph and a reduction in concept duplication that might arise from identical or closely related concepts in different ontologies.
LakeFS
LakeFS operates as a largely S3-compliant object storage interface which also
retains the concept of a git-like commit and change tracking function. Because
of the capacity to track checkouts and changes, LakeFS can be called by a
related RENCI-developed tool (avalon) to do change detection in successive
runs of the data pipelines. If LakeFS detects no changes in the input data of a
step, the step can then be skipped, allowing for a dramatic decrease in
processing time on re-indexing runs.